布隆过滤器的原理、应用场景和源码分析实现
本文共 1889 字,大约阅读时间需要 6 分钟。
原理
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样: 如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1。 例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1。 例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为: 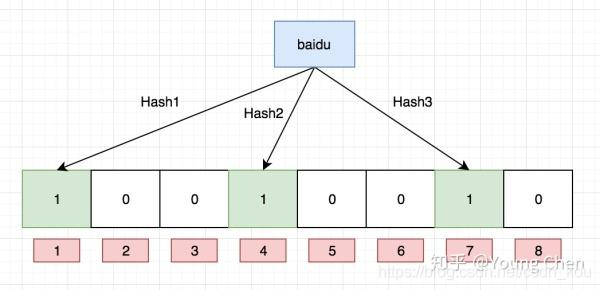 Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为: 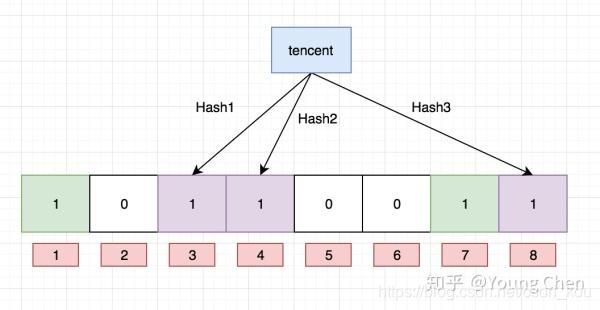 值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。 现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。
而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
作者:YoungChen__
链接:特点
- 可以判断某一个数一定不存在
- 不可以判断某一个数一定存在
应用场景
- 海量URL的去重
源码实现
- 三个哈希函数
unsigned int SDBMHash(char *str, unsigned int size){ unsigned int hash = 0; while (*str) { // equivalent to: hash = 65599*hash + (*str++); hash = (*str++) + (hash << 6) + (hash << 16) - hash; } return (hash & 0x7FFFFFFF) % size;}// RS Hash Functionunsigned int RSHash(char *str, unsigned int size){ unsigned int b = 378551; unsigned int a = 63689; unsigned int hash = 0; while (*str) { hash = hash * a + (*str++); a *= b; } return (hash & 0x7FFFFFFF) % size;}// JS Hash Functionunsigned int JSHash(char *str, unsigned int size){ unsigned int hash = 1315423911; while (*str) { hash ^= ((hash << 5) + (*str++) + (hash >> 2)); } return (hash & 0x7FFFFFFF) % size;} - 插入并给指定位置置1
void BFInsert(BloomFilter *pBF, const char *str){ unsigned int i1 = pBF->func1(str, pBF->bm.size); unsigned int i2 = pBF->func2(str, pBF->bm.size); unsigned int i3 = pBF->func3(str, pBF->bm.size); BMSetOne(&(pBF->bm), i1); BMSetOne(&(pBF->bm), i2); BMSetOne(&(pBF->bm), i3);} 优质参考文献
转载地址:http://joorb.baihongyu.com/
你可能感兴趣的文章
Linux 系统挂载数据盘
查看>>
Git基础(三)--常见错误及解决方案
查看>>
Git(四) - 分支管理
查看>>
PHP Curl发送数据
查看>>
HTTP协议
查看>>
HTTPS
查看>>
git add . git add -u git add -A区别
查看>>
apache下虚拟域名配置
查看>>
session和cookie区别与联系
查看>>
PHP 实现笛卡尔积
查看>>
Laravel中的$loop
查看>>
CentOS7 重置root密码
查看>>
Centos安装Python3
查看>>
PHP批量插入
查看>>
laravel连接sql server 2008
查看>>
Laravel 操作redis的各种数据类型
查看>>
Laravel框架学习笔记之任务调度(定时任务)
查看>>
laravel 定时任务秒级执行
查看>>
浅析 Laravel 官方文档推荐的 Nginx 配置
查看>>
Swagger在Laravel项目中的使用
查看>>